Agents are making filesystems cool again

by Wayne Duso and Nancy Wang
February 13, 2026 - 8 min

Related Categories
Agent swarms are having a moment.
The AI headlines of early 2026 have been dominated by stories where swarms of hundreds or thousands of agents have worked together to accomplish staggeringly complex tasks.
These swarms broadly fall into two types. To quote my 1Password colleague, Jeff Malnick, “There are controlled swarms, such as Cursor’s web browser demo, that operate within clearly defined boundaries. There are also uncontrolled swarms, such as OpenClaw, that run with broad, implicit access to user machines and assets.”
Both types of swarms have undeniably impressive capabilities, but they also have serious limitations. Right now, many of these systems only work because they implicitly inherit access to a developer’s machine, filesystem, network, and their credentials. That level of unfettered access may work in a sandbox, but it is not viable for production.
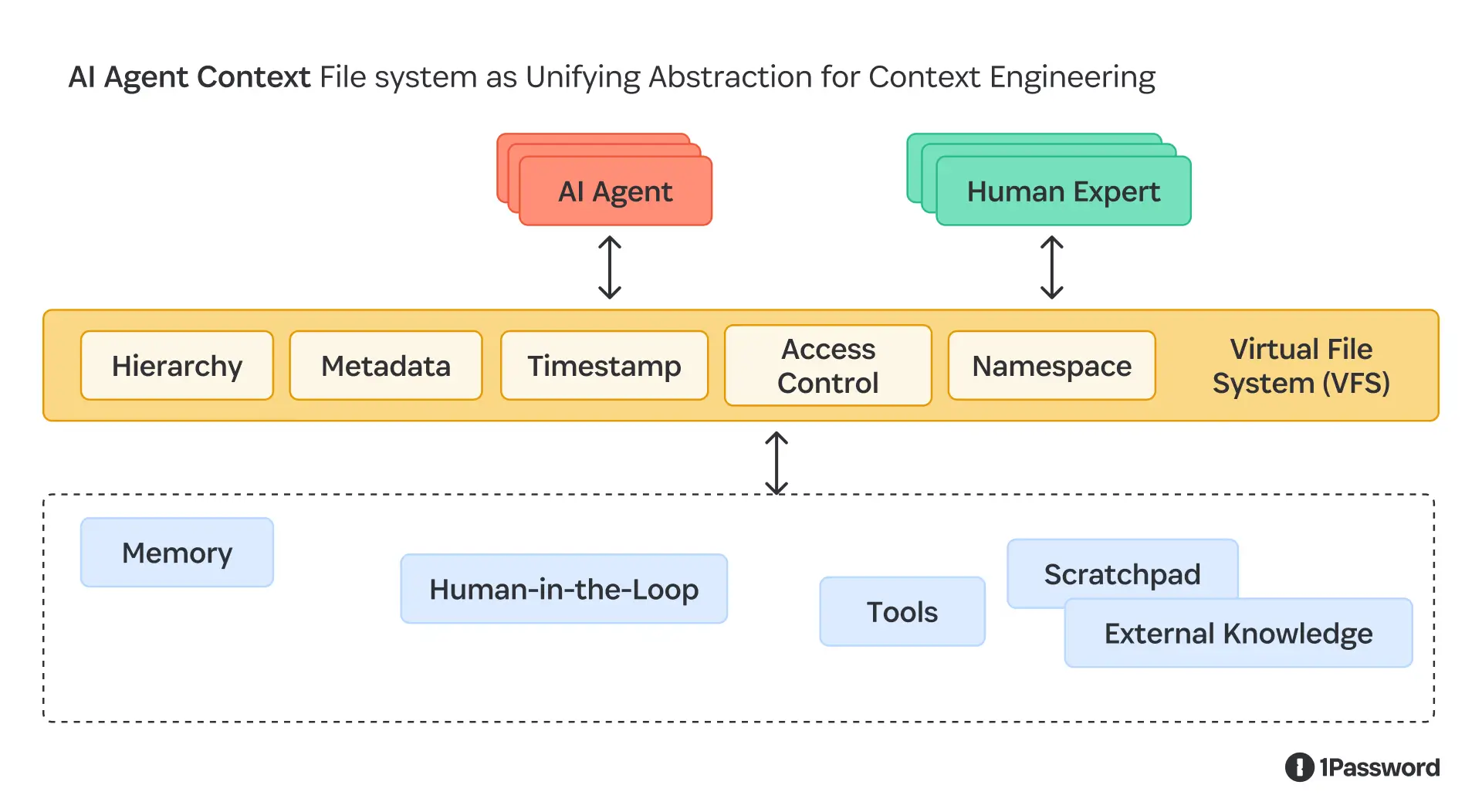
What is becoming clear is that the hardest problem with agent swarms is not prompting, planning, or model choice. It is abstraction and isolation. Isolating using virtual machines or containers works great for compute. Isolating data with virtual disks works well too. But swarms work best when they can securely share context, results, documents, and more. They do so using files and filesystems, as every operating system and programming language provides agents all the tools they need, ready to use, for reading, writing, sharing, searching, and organizing their context, memory, and results. And thus, file systems are cool again.
Filesystems give agents a universal, durable abstraction for memory and coordination.
What they do not give you is a way to express intent, authority, or accountability at the level agents operate.
Filesystems are necessary for swarms, but combining them with an identity control layer begins to truly point us in the direction of what production-ready swarms can look like.
Why filesystems work for agents (and why that surprised everyone)
At first glance, it is odd that something as long-lived as the filesystem has become the center of modern agent systems. We have databases, vector stores, APIs, and purpose-built orchestration frameworks. Surely one of those should be the right abstraction.
And yet, when you look at what actually works in practice, agent systems keep converging on the filesystem.
The reason for this is more about coordination than storage.
Agents don’t just need memory. They need a workspace: a place to externalize partial results, evolve plans, share artifacts, and revisit prior work without dragging everything through a context window. Filesystems provide this naturally. They allow agents to persist state cheaply, load it incrementally, and discard it when it is no longer relevant. This lets agents work on problems that are larger than their immediate context without pretending that everything must fit in a single prompt.
Just as importantly, filesystems align with how models already operate. Modern models are deeply trained on code, repositories, logs, diffs, and shell workflows. Navigating directories, inspecting files, grepping for details, and comparing changes are native behaviors for agents. A filesystem is largely self-describing, which means agents can discover what matters without being taught a new API or paying a constant context tax to remember how a tool works.
This advantage compounds as soon as you move beyond a single agent.
With multiple agents, the problem shifts from reasoning to coordination. Filesystems scale here because they offer a shared, addressable namespace. Agents do not need to synchronize through tight coupling or complex protocols. They coordinate by producing and consuming artifacts. One agent writes a plan, another refines it. One agent generates data, another audits it. Failures stay localized, late-joining agents can inspect the current state, and parallel work becomes the default rather than the exception.
Equally critical is that filesystems give you something most swarm demos lack: auditability. Every meaningful action leaves a trail. Changes can be inspected, diffed, attributed, and rolled back. When something goes wrong, you can ask what happened and get an answer. This transparency is a prerequisite for letting agents interact with real systems.
Filesystems also provide a clean boundary for authority. Instead of reasoning about which tools an agent may call or which parameters are safe, you reason about which paths it can read or write, for how long, and under which identity. That boundary is easy to understand, easy to revoke, and easy to monitor. It mirrors the isolation models we already rely on for containers, CI systems, and distributed workloads.
None of this means filesystems replace everything. Structured, schema-stable data still belongs in databases. But agents operate in a world of messy, evolving artifacts: plans, logs, intermediate outputs, code, documents, and checkpoints. Filesystems accept all of this without forcing premature structure, which is exactly what makes them effective as shared context.
The deeper shift is that filesystems are no longer just a place to dump data. They are becoming the dependency layer for agent state. Instead of bundling all context up front or granting broad ambient access, agents can declare what data they depend on and materialize only what they need. That makes agents portable, reproducible, and composable in ways that ad-hoc tool integrations never quite achieve.
This is why filesystems keep reappearing at the center of agent architectures. They do not make agents smarter. They make them legible, controllable, and scalable. And once you start running swarms instead of demos, those properties matter more than anything else.
Why the solution becomes a fault line
Both host and shared filesystems are a proven abstraction and tool for agents and agent swarms. It is the most natural place to put shared state. It requires little to no exotic or bespoke tooling or systems. On a host, every process can access the file system. On a network, every client can potentially mount and modify a shared file system if their permissions and identity are too promiscuous. Simply write context memory, logs, and other intermediate artifacts into a well-structured directory, move on and pick up at any time.
That convenience is also the problem.
For example, once an agent has access to the host filesystem, it effectively inherits the authority of the machine. It can read any file, regardless of whether it was meant to be seen or not. It can persist state forever. It can interfere with other co-located agents in ways that are subtle and challenging to debug. The same can be true for large swarms coordinating in a networked or cloud environment using a networked file system.
This is similar to a class of failure we saw before containers and virtual machines became mainstream. The convenience of shared disks and shared state worked until it didn’t, and when they failed, the blast radius was often massive.
For swarms, a shared filesystem defines what an agent can know and what it can affect. If that boundary is fuzzy, everything built on top of it becomes hard to reason about.
The missing piece for production-ready swarms
The current approaches to managing swarms break down when we attempt to move them from the sandbox to the real world.
Swarms work in demos because everything runs on a single machine with a human nearby. They fail in production because there is no durable runtime and no clean way to manage authority over time.
Without isolation, you can’t answer questions like:
Which agent touched this file?
Why did it have access?
Can we revoke that access right now?
What state is safe to keep and what should be discarded?
Answering these questions requires a system that operates at execution time, not just at storage time.
Something has to issue identity to agents, bind that identity to scoped authority, and enforce it continuously as agents run.
Running distributed systems in the cloud forced us to confront these questions years ago. Agent swarms need that same level of rigor in order to be allowed to make contact with real infrastructure.
Building the identity layer for AI swarms
If you want to run swarms outside of demos, a few things become non-negotiable.
You need a persistent runtime where agents can live longer than a single task. That runtime has to handle isolation, coordination, and state without resorting to machine-level access.
Agents need explicit identity from the moment they are created. Every action needs to be attributable. Access needs to be scoped, time-bound, and revocable.
This is the role 1Password is evolving toward for agents.
We already sit at the point where identity, credentials, and sensitive actions meet execution. As agents move into production, that same control point becomes the natural place to broker agent identity, grant just-in-time access, and revoke it while agents are still running.
Finally, swarms need to operate autonomously most of the time, while still requiring oversight for high-risk actions. That requires a clean separation between what agents are allowed to do and what requires approval.
In practice, this turns the filesystem into a capability surface rather than a free-for-all disk.
Agents still read and write files. Tools still speak POSIX. What changes is that every filesystem operation is backed by an identity, a policy decision, and a lease.
None of this is exotic. These are the same requirements we learned to enforce for distributed systems. We just have to apply them to agents.

